最近一段時間,系統新版本要發布,在beta客戶測試期間,暴露了很多問題,除了一些業務和異常問題外,其他都集中在性能上。有幸接觸到這些性能調優的機會,當然要學習總結了。性能優化是一個老生常談的問題了,典型的性能問題如頁面響應慢、接口超時,服務器負載高、并發數低,數據庫頻繁死鎖等。而造成性能問題又有很多種,比如磁盤I/O、內存、網絡、算法、大數據量等等。我們可以大致把性能問題分為四個層次:代碼層次、數據庫層次、算法層次、架構層次。所以下面騰科小編會結合實際性能優化案例,和大家分享下性能調優的工具、方法和技巧。
說到性能問題,你可能首先就想到的是麻煩或者頭大,因為一般性能問題都比較緊急,輕則影響客戶體驗,重則宕機導致財務損失,而且性能問題比較隱蔽,不易發現。因此一時間無從下手,而這時我們就很容易從心底開始去排斥它,不愿接這燙手的山芋。而恰巧,性能調優是體現程序員水平的一個重要指標。因為處理bug、崩潰、調優、入侵等突發事件比編程本身更能體現平庸程序員與理想程序員的差距。當面對一個未知的問題時,如何定位復雜條件下的核心問題、如何抽絲剝繭地分析問題的潛在原因、如何排除干擾還原一個最小的可驗證場景、如何抓住關鍵數據驗證自己的猜測與實驗,都是體現程序員思考力的最好場景。是的,在衡量理想程序員的標準上,思考力比經驗更加重要。所以,若你不甘平庸,請擁抱性能調優的每一個機會。當你擁有一個正確的心態,你所面對的性能問題就已經解決了一半。
拿到一個性能問題,不要忙著先上工具,先了解問題出現的背景,問題的嚴重程度。然后根據自己的經驗積累作出預估。比如客戶來了個性能問題說系統宕機了,已經造成資金損失了。這種涉及到錢的問題,大家都比較敏感,根據自己的level,決定是否要接這個鍋。這不是逃避,而是自知之明。了解問題背景之后,下一步就來嘗試問題重現。如果在測試環境能夠重現,那這種問題就很好跟蹤分析。如果問題不能穩定重現或僅能在生產環境重現,那問題就相對比較棘手,這時要立刻收集現場證據,包括但不限于抓dump、收集應用程序以及系統日志、關注CPU內存情況、數據庫備份等等,之后不妨再嘗試重現,比如恢復客戶數據庫到測試環境重現。不管問題能否重現,下一步,我們就要大致對問題進行分類,是代碼層次的業務邏輯問題還是數據庫層次的操作耗時問題,又或是系統架構的吞吐量問題。那如何確定呢?而我傾向于先從數據庫動手。我的習慣做法是,使用數據庫監控工具,先跟蹤下Sql耗時情況。如果監控到耗時較長的SQL語句,那基本上就是數據庫層次的問題,否則就是代碼層次。若為代碼層次,再研究完代碼后,再細化為算法或架構層次問題。確定問題種類后,是時候上工具來精準定位問題點了:
- Sql耗時問題,推薦使用免費的Plan Explorer分析執行計劃。
- 代碼問題定位,優先推薦使用VS自帶的Performance Analysis,其次是RedGate的性能分析套件.NET Developer Bundle;然后還有Jet Brains的dotTrace -- .NET performance profiler,dotMemory-- .NET memory profiler;再然后就是反人類的Windbg;等等。
精準定位問題點后,就是著手優化了。相信到這一步,就是優化策略的選擇了,這里就不展開了。優化后,最后當然要進行測試了,畢竟優化了多少,我們也要做到心里有譜才行。以上啰啰嗦嗦有點多,下面我們直接上案例。
由于前幾天剛學會用RedGate的分析工具,拿到這個問題,本地嘗試重現后,就直接想使用工具分析。然而,這工具在使用webdev模式起站點時,總是報錯,而當時時一根筋,老是想解決這個工具的報錯問題。結果,白白搞了半天也沒搞定。最后不得已放棄工具,轉而選擇使用sql server profiler去監控sql語句耗時。一跟蹤不要緊,問題就直接暴露了,整個全屏的重復sql語句,如下圖。
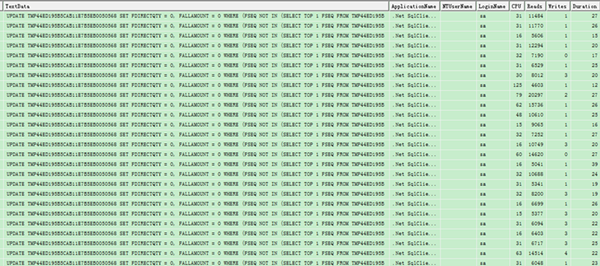
這下問題就很明顯了,八成是代碼在循環拼接sql執行語句。根據抓取到sql關鍵字往代碼中去搜索,果然如此。
#region更新三張表數據結合的中間臨時表數據,有上游單據的直接調撥單分多次下推時,只計算一次的調撥數量和價稅合計
string sSql = string.Format(@
"SELECT FENTRYID FROM {0} GROUP BY FENTRYID HAVING COUNT(FENTRYID) > 1", sJoinDataTempTable);
using(IDataReader reader = DBUtils.ExecuteReader(this.Context, sSql)) {
while (reader.Read()) {
sbSql.AppendFormat(@"
UPDATE {0} SET FDIRECTQTY = 0,FALLAMOUNT = 0
WHERE FSEQ NOT IN (
SELECT TOP 1 FSEQ FROM {0} WHERE FENTRYID = {1}) AND FENTRYID = ({1});"
, sJoinDataTempTable, Convert.ToInt32(reader["FENTRYID"]));
listSqlObj.Add(new SqlObject(sbSql.ToString(), new List < SqlParam > ()));
sbSql.Clear();
}
}
#endregion
看到這段代碼,咱先不評判這段代碼的優劣,因為畢竟代碼注釋清晰,省了理清業務的功夫。這段sql主要是想做去重處理,很顯然選用了錯誤的方案。改后代碼如下:
string sqlMerge = string.Format(@"
merge into {0} t1
using(
select min(Fseq) fseq,Fentryid from {0} t2 group by fentryid
) t3 on (t1.fentryid = t3.fentryid and t1.fseq <> t3.fseq)
when matched then
update set t1.FDIRECTQTY = 0, t1.FALLAMOUNT = 0
", sJoinDataTempTable);
listSqlObj.Add(new SqlObject(sqlMerge, new List < SqlParam > ()));
sbSql.Clear();
改后測試相同數據量,耗時由10mins降到10s左右。
拿到這個問題后,本地重現后,監控sql耗時沒有異常,那就著重分析代碼了。因為可發量校驗的業務邏輯極其復雜,又加上又直接再一個類文件實現該功能,3500+行的代碼,加上零星注釋,真是讓人避之不及。逃避不是辦法,還是上工具分析一把。這次我選用的時VS自帶的Performance Profiler,開發環境下極其強大的性能調優工具。針對我們當前案例,我們僅需要跟蹤指定服務對應的dll即可,使用步驟如下:
- Analyze-->Profiler-->New Performance Session
- 打開Performance Explorer
- 找到新添加的Performance Session,右鍵Targets,然后選擇Add Target Binary,添加要跟蹤的dll文件即可
- 將應用跑起來
- 選中Performance Session,右鍵Attach對應進程即可跟蹤分析性能了
- 在跟蹤過程中,可隨時暫停跟蹤和停止跟蹤
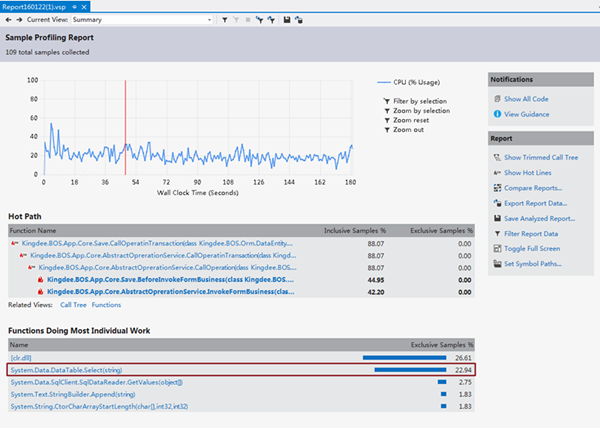
跟蹤結束后本案例跟蹤到的采樣結果如下圖:
同時Performance Profiler也給出了問題的建議,如下圖:
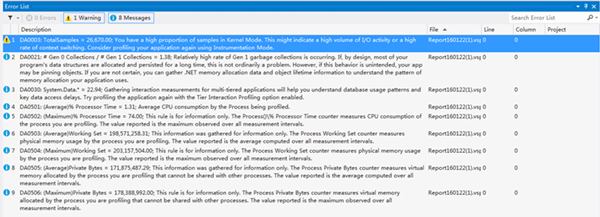
其中第1、4條大致說明程序I/O消耗大,第一代的GC上存在未及時釋放的垃圾占比過高。而根據上圖的采樣結果,我們可以直接看出是由于再代碼中頻繁操作DataTable引起的性能瓶頸。走讀代碼發現的確如此,所有的數量統計都是在代碼中循環遍歷DataTable進行處理的。而最終的優化策略,就相當于一次大的重構,將所有代碼中通過遍歷DataTable的計算邏輯全部挪到SQL中去做。由于代碼過多,就不再放出。
案例3:客戶反饋批量引入1000張訂單,耗時40mins左右,且容易中斷。
同樣,我們還是先嘗試本地重寫。經測試批量引入101張單據,就耗時5mins左右。下一步打開Sql監控工具也未發現耗時語句。但考慮到是批量導入操作,雖然單個耗時不多,但乘以100這個基數,就明顯了。下面我們就使用RedGate的Ants Performance Profiler跟蹤一下。
該工具比較直觀,可以同時監控代碼和SQL執行情況。第一步,New Profiler Session,第二步進行設置,如下圖。根據自己的應用程序類別,選擇相應的跟蹤方式。
針對這個問題,我們跟蹤到的調用堆棧和SQL耗時結果如下圖:
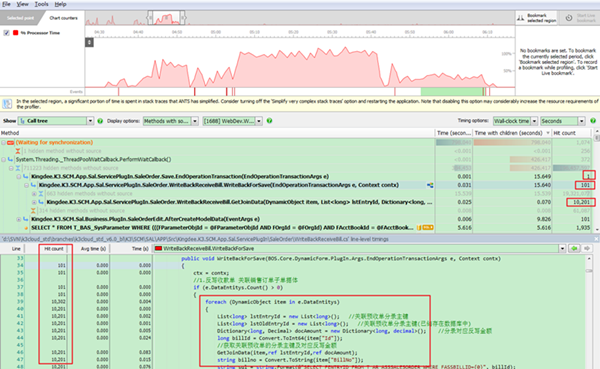

首先從調用堆棧中的Hit Count,我們可以首先看出它是一個批量過程,因為入口函數僅調用一次;第二個我們可以代碼中是循環處理每一個單據,因為Hit Count與我們批量引入的單據數量相符;第三個,突然來了個10201,如果有一定的數字敏感性的話,這次性能問題的原因就被你找到了。這里就不賣關子了,101 x 101 = 10201。
是不是明白了什么,存在循環嵌套循環的情況。我們走讀代碼確定一下:
//Save.cs
public override void EndOperationTransaction(EndOperationTransactionArgs e) {
//省略其他代碼
foreach(DynamicObject dyItem in e.DataEntitys) {
//反寫收款單
WriteBackReceiveBill wb = new WriteBackReceiveBill();
wb.WriteBackForSave(e, this.Context);
}
}
//WriteBackReceiveBill .cs
public void WriteBackForSave(EndOperationTransactionArgs e, Context contx) {
//省略其他代碼:
foreach(DynamicObject item in e.DataEntitys) {
//do something
}
}
好嘛,外層套了一個空循環卻什么也沒做。修改就很簡單了,刪除無效外層循環即可。













